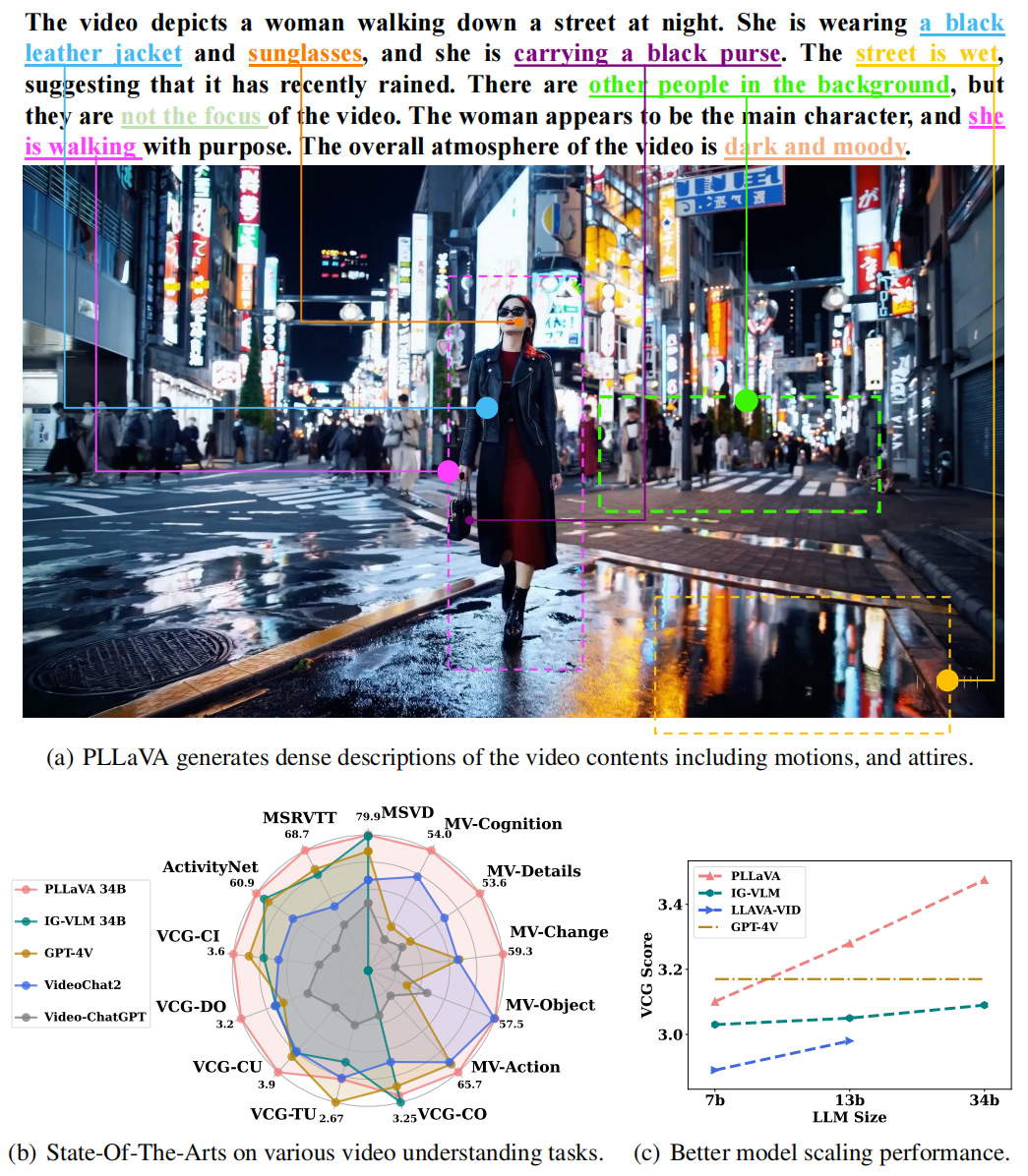
说明:起猛了,大模型能够理解视频了?来探索PLLaVA叭!
目录
一、为什么提出PLLaVA
1.1 Motivation总述
背景: 多模态大模型(MLLMs)在大规模image-text对的训练中显示出显著的图像理解能力,最近的视频理解模型也探索了大规模视频文本数据上微调LLMs的类似pipeline。
因为LLMs是处理序列的原生方法,并且能够理解时间信息。所以,直观的方法是将多个视频帧编码为序列,并直接输入到MLLMs。
-
问题一: 现有方法的计算资源和视频标注成本高。
-
问题二: 与zero-shot applications相比,在视频数据上训练image MLLM并不能够提高性能,而且由于inquiry prompts的改变引起了性能问题(performance vulnerability)。
- 由于图像编码器能够编码的信息有限。
-
问题三: 增加语言模型组件的大小不能提高视频理解性能。
- 由于视频数据集质量比图像数据集更差。视频的描述可能很短,因此,当模型从视频数据集中学习时间描述时,其他指标(如对象和空间关系)的描述会降低。LLM越强,输出衰减越快。
1.2 问题探究
-
IND prompt: 即In-Distribution 提示,也就是训练时采用的提示。
-
OOD prompt: 即Out-Of-Distribution提示,与IND分布不同的提示。
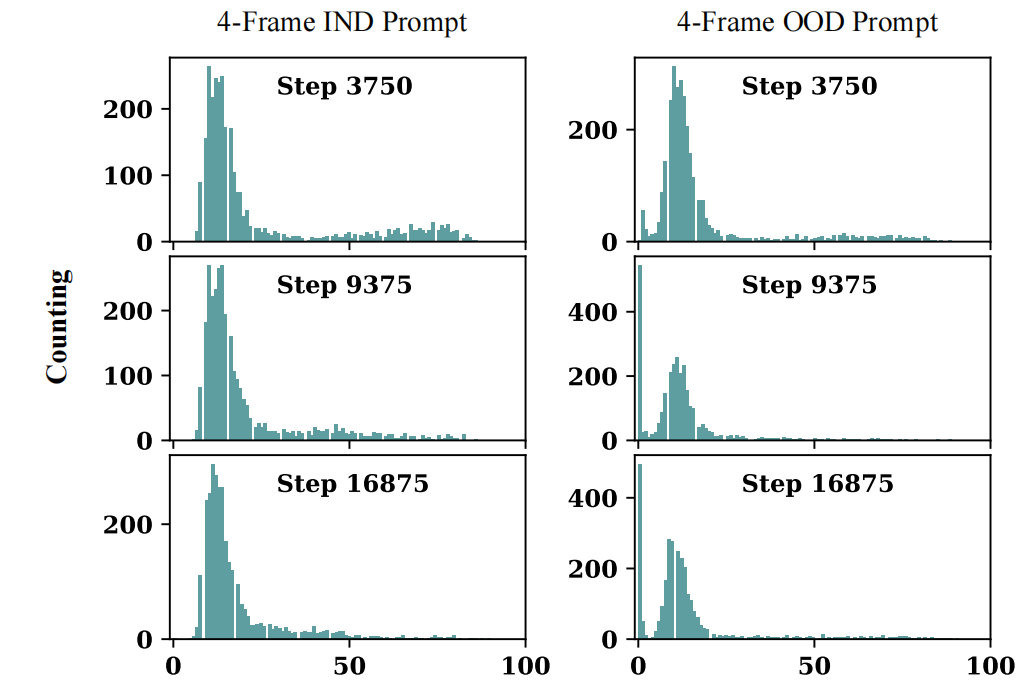
当用4帧的视频输入微调LLaVa时,发现有一些visual token的范数明显大于其它visual token。这些tokens导致了较短的文本描述和较低的质量。更糟糕的是:如果prompt模板改变,学习到的MLLMs将完全崩溃,导致相当短的描述,甚至没有响应。如下图所示:从上到下,随着训练的数据样本增多,优势token(有着高范数的token)出现并增加,特别是在OOD提示下。

随着训练样本的增加,4帧的模型更倾向于生成更短的文本。(注意看OOD的0处的counting,直接大到飞起!)作者推测:由于self-attention中的softmax计算,导致范数大的token获得了全局视频信息,从而抑制了其它token的范数。所以导致生成的描述很短。
二、PLLaVA模型思路
2.1 问题一解决思路
通过实验发现:添加更多的视频帧可以减轻大token抑制小token的情况。然而,这将会导致更大的内存消耗。
因此,需要存在一种trade-off(权衡) between 帧数和计算成本。直观的方法是对视频帧进行下采样 ,然而像VideoChatGPT那样直接对空间维度和时间维度进行平均会丢失太多的空间信息,并且在训练数据集的缩放过程中也无法获得最佳性能。
于是,目标是找到不降低scaling curve(可扩展性曲线)的每帧的最小空间分辨率。对此,PLLaVa使用了池化操作来探索最佳位置
scaling curve(可扩展曲线): 表示随着系统资源增加,系统性能如何变化的曲线。理想情况下,当资源加倍时,性能也应该加倍,这被称之为线性可扩展性。但是,在实践中,由于通信开销、负载均衡问题和其他因素,往往表现出亚线性可扩展性。
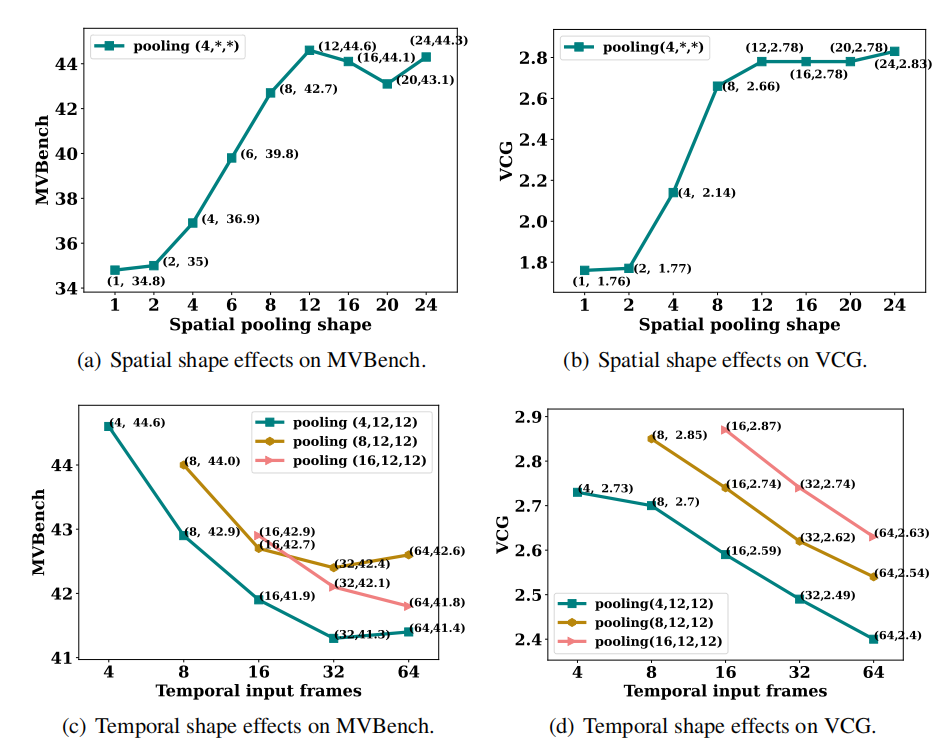
池化层设计主要在时间和空间上完成。因此,需要找出两个问题的答案:1)哪个维度更适合池化以节省成本? 2)沿着该维度的最大压缩比是多少?
为了实现上面的两个目标,基于LLaVa-1.5 7B模型绘制了模型曲线。选取(4,24,24,d)的输入视频特征,其中4为帧数(时间维度),24×24是帧特征的原始空间维度,d是每个visual token的嵌入维度。
首先,控制帧数为4,得到一组空间维度,这些空间维度的MVBench和VGG性能如图所示。可以观察到,将空间维度下采样50% 不会降低模型的性能 ,进一步降低空间维度会导致性能显著下降。
然后,固定空间维度为12×12,选择了(4,12,12)、(8,12,12)和(16,12,12)三个形状的池化层。例如:从(64,24,24)池化到(4,12,12)表示每16帧融合一次,则下采样率为6.25%。实验发现:沿着时间维度进行池化往往会降低模型性能。
2.2 问题二解决思路
PLLaVa选择探索架构和优化算法,而不是构建高质量的视频数据集,以便在学习视频数据集的时间信息时更好地保留图像数据集中的学习信息。因此,利用了权重融合的技巧。设置了两组权重:一组来自图像预训练,另一组来自视频数据集微调。训练结束后,寻找基于图像的模型权值和基于视频的模型权值的最优组合,希望组合后的模型能同时从两个数据集中获益。本文将此过程称为训练后优化,其影响如下图所示:
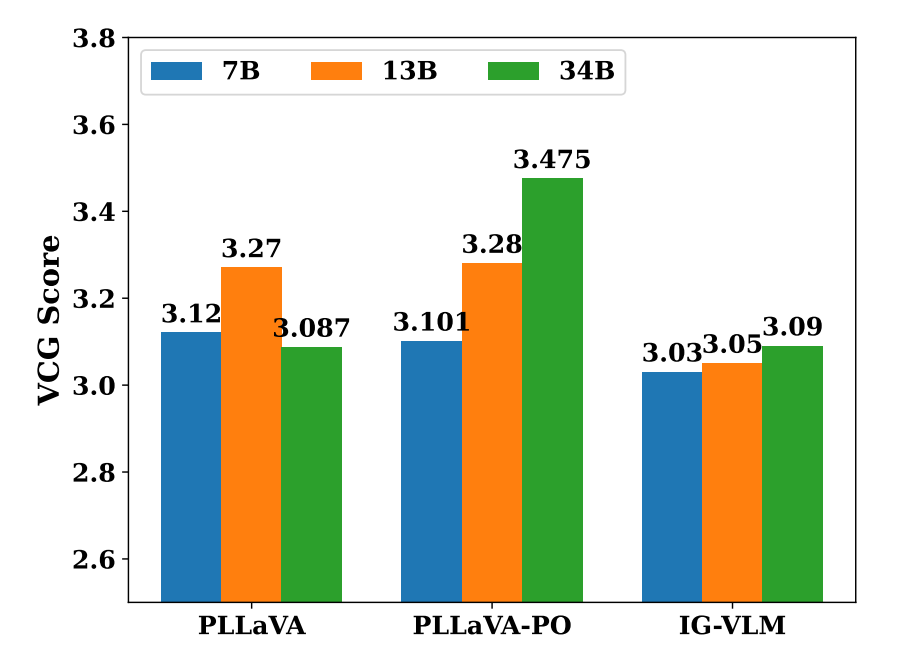
根据上图可以看到:PLLaVA随着模型变大,效果并不能变得更好。但是优化后的PLLaVA-PO就能够随着模型变大,效果变得更好啦!
三、PLLaVA贡献
-
引入了一种简单但非常有效的池化策略,该策略系统地平衡了训练效率和准确性。
-
引入了训练后优化的模型权重合并方法,可以有效减少多模态微调过程中大语言模型遗忘的现象。
-
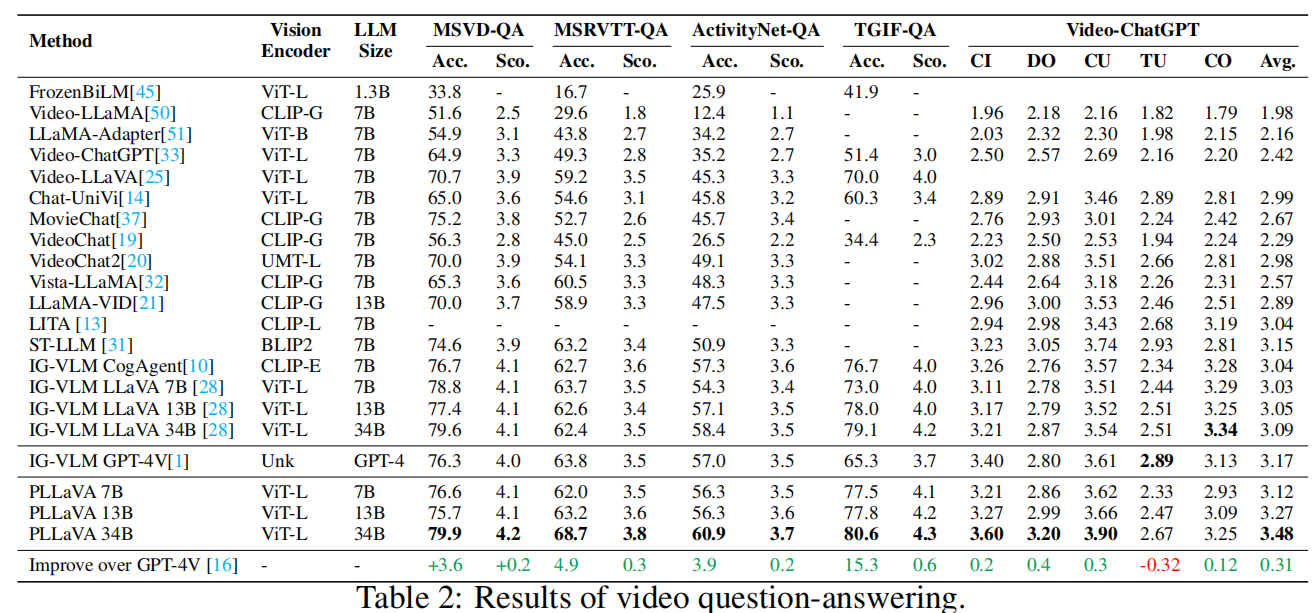
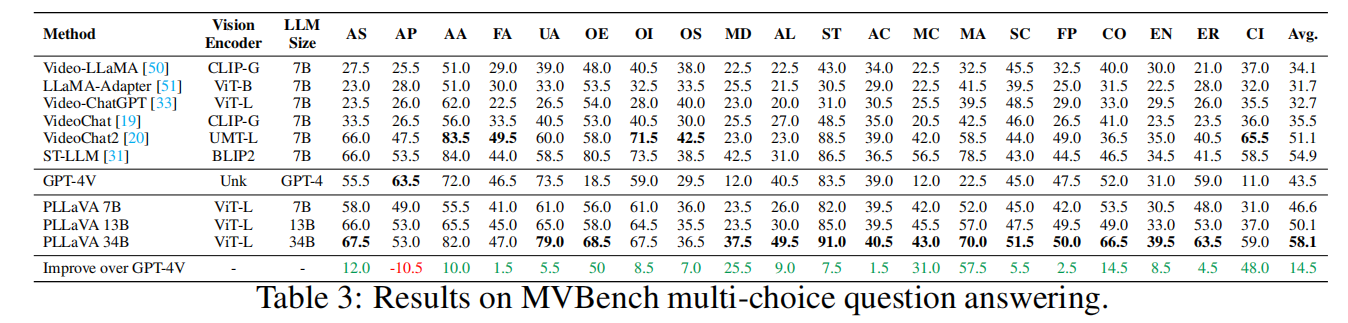
达到了多个SOTA,特别是对于密集字幕的视频字幕任务。通过Pool-LLaVA,对Panda-70M中排名前1M的视频数据进行了重配,配上了高密度、准确的双语字幕。
四、PLLaVA模型讲解
4.1 Image MLLMs应用失败分析
首先,将图像MLLMs适应到视频域的直接方法:使用图像编码器对选定的视频帧进行编码,并将这些帧特征连接作为图像MLLMs的输入。这是为了利用LLMs的能力来解释编码视频帧中的时间信息,这个方法称之为 $n-frame$ 。
具体而言,给定视频帧序列 $X∈\mathbb{R}^{T×C×W×H}$,通过CLIP-ViT模型中预训练的视觉编码器获得每一帧的特征,编码后的帧特征表示为 $X_v∈\mathbb{R}^{T×w×h×d}$。$n-frame$ 表示为:
\[r=MLLM(X_v,X_t)\]其中, $X_t$表示输入文本,$r$是输出文本。在此场景训练MLLM的过程中,遇到了两个问题:
①易受到提示的影响 Vulnerability to prompts. 在处理生成任务时,用$n-frame$ 训练的模型可能对prompt 框架高度敏感。
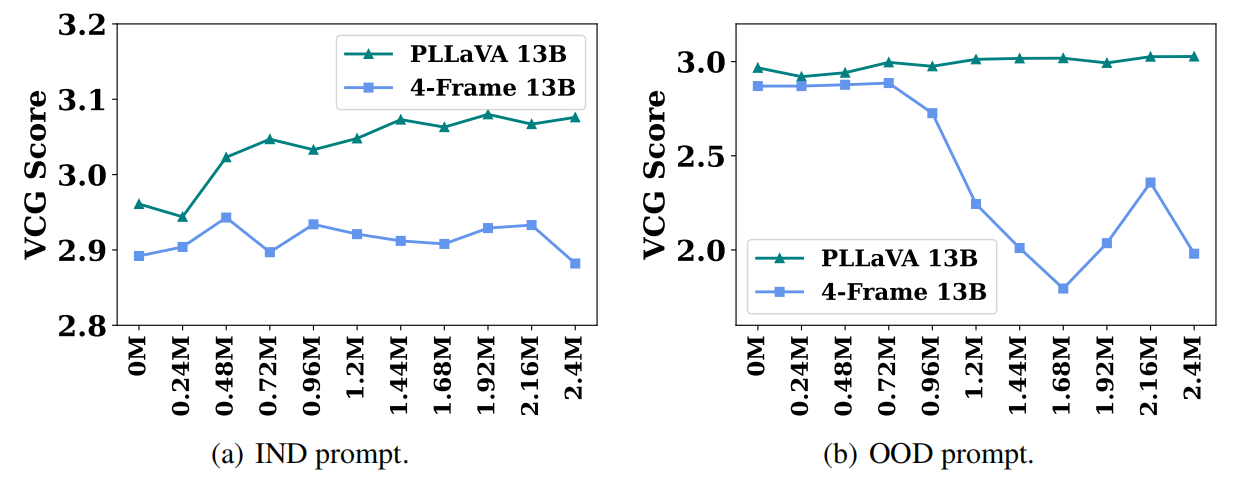
下图说明了这种现象。将提示分为两类:in-distribution(IND) 和Out-of-Distribution(OOD),在IND下生成时,尽管随着训练的数据样本越多,模型有生成长度越短的趋势,但仍然可以生成较好的视频描述。
然而,如果用OOD,其中只是更改了对话中两个角色的标签,那么生成的响应的质量就会急剧下降。在训练了3750步的模型下,生成的内容长度正常。然而,对于训练时间较长的模型,在7500步时生成较短,在11250步时甚至没有响应。这个例子展示了$n-frame$ 方法的脆弱性。
②Dominant tokens. 随着训练样本的增加,出现Dominant tokens(具有高范数)的趋势,如下图所示。此外,当用更多的数据训练时,twin-tower distribution 双塔分布要宽得多。因此,推测这些Dominant tokens与OOD prompt下的token退化之间存在相关性。$n-frame$ 提出的PLLaVA之间的分布比较可以进一步验证该猜想,下面会讲到哈。
③数据扩展失败 Data scaling failures. 下图展示了$n-frame$ 在不同训练样本下的性能曲线。在IND prompt下,保持停滞。在OOD prompt下,训练样本超过0.48M后,性能会下降很多。
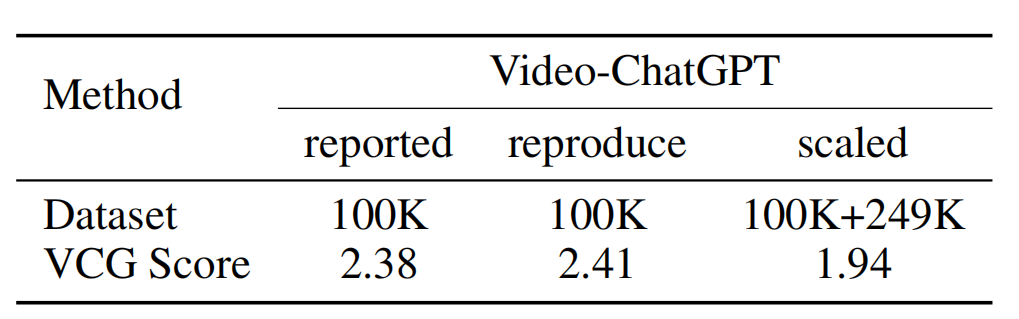
在VideoChatGPT实验结果中,也发生了类似情况(见下图,第三列引入了额外的训练数据,导致性能显著下降)。VideoChatGPT引入了一种独特的池化策略 ,涉及到时间维度和空间维度上的平均视觉特征,从而在连接两个维度后得到视觉特征$X_{vcg}∈\mathbb{R}^{(T+w×h)×d}$,然后再生成响应。
4.2 模型缩放退化 Model Scaling Degradation
通过调研,增加模型大小并不会让模型的性能有显著改善。
通过绘制IG-VLM和PLLaVA之间性能对比,发现IG-VLM的7B、13B和34B几乎没有差别,在没改良的PLLaVA情况下,34B模型反而越差。
4.3 PLLaVA模型
Motivation:$n-frame$ 和VideoChatGPT都期望以图像为中心的MLLMs适应视频域的复杂性,但是遇到了问题。$n-frame$ 由于内存限制引入了少量的帧,而VideoChatGPT通过池化策略压缩了超过100帧的信息。然而,结果是相似的。
考虑到时间信息的必要性和处理超长视频输入的成本,池化是一种直观而简单的方式来满足这两种需求。上述两个问题可能源于帧信息的不充分和对帧特征的处理不当。因此,深入研究了MLLMs中使用的视频特征池化策略。
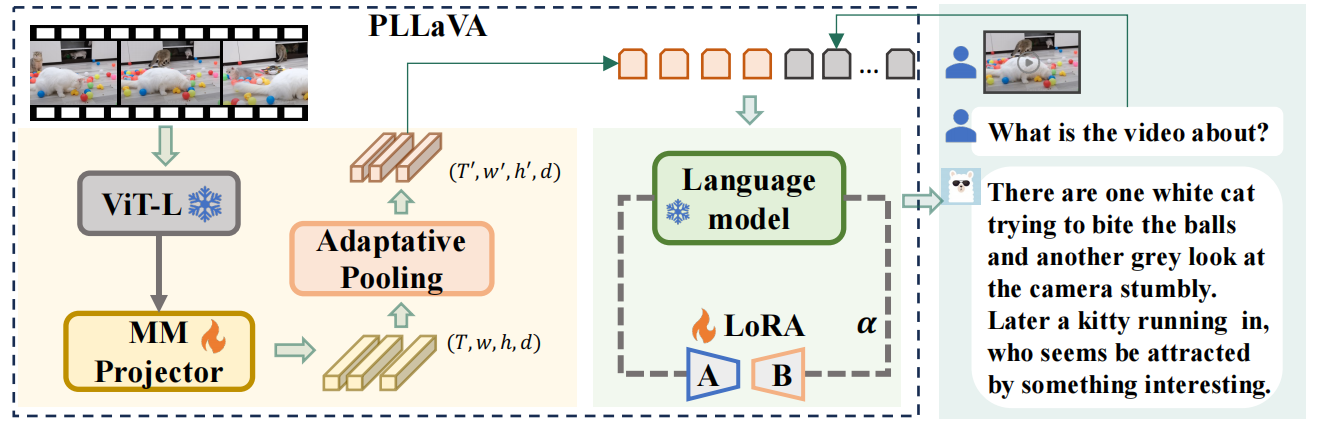
Pipelne: PLLaVA框架首先通过冻结的ViT-L和MM Projector对用户的视频进行处理,得到形状为 $(T,w,h,d)$的视觉特征。接着,将这些特征通过一个无参数的Adaptative Pooling 自适应池化模块,有效降低了时间和空间维度,得到形状为 $(T’,w’,h’,d)$ 的视觉特征。
\[X_{vp}=AdaptStructPooling(X_v|T'×w'×h')\]然后,将特征展开并且和文本输入嵌入(用户的问题)连接起来,作为图像LLMs的输入,以生成对用户的响应。还使用了LoRA模块,使得LLM适应和视频相关的生成任务。最后,将图像LLMs的权重和视频样本下学习到的LoRA权重融合。
4.4 训练后优化
由于低质量视频文本数据样本上训练导致LLM能力下降。为了缓解该问题,提出了一种video MLLMs参数训练后优化的方法。涉及将视频数据上训练好的LLM与基础图像的原始LLM混合。
对于LLM参数为 $W_0$和给定输入$X_{vp}$,可以获得LoRA微调LLM输出的隐藏层状态:
\[h=W_0X_{vp}+\frac{\alpha}{r}\Delta{WX_{vp}}\]其中,$\Delta{W}$为低秩可学习参数,$\frac{\alpha}{r}$ 用于缩放学习到低秩权重。在推理过程中,通过改变$\alpha$值来调整原始LLM和训练后LLM之间的混合比例(包含LoRA权重),实验表明,较低的$\alpha$可以显著提高生成性能。
五、PLLaVA实验部分
那效果包的很不错!直接看下面的演示: