说明:24年6月的一篇Vid-LLM综述…
目录
一、Video Understanding
- 论文链接: https://arxiv.org/pdf/2312.17432
- Github链接: https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding
1.1 Video Understanding任务
-
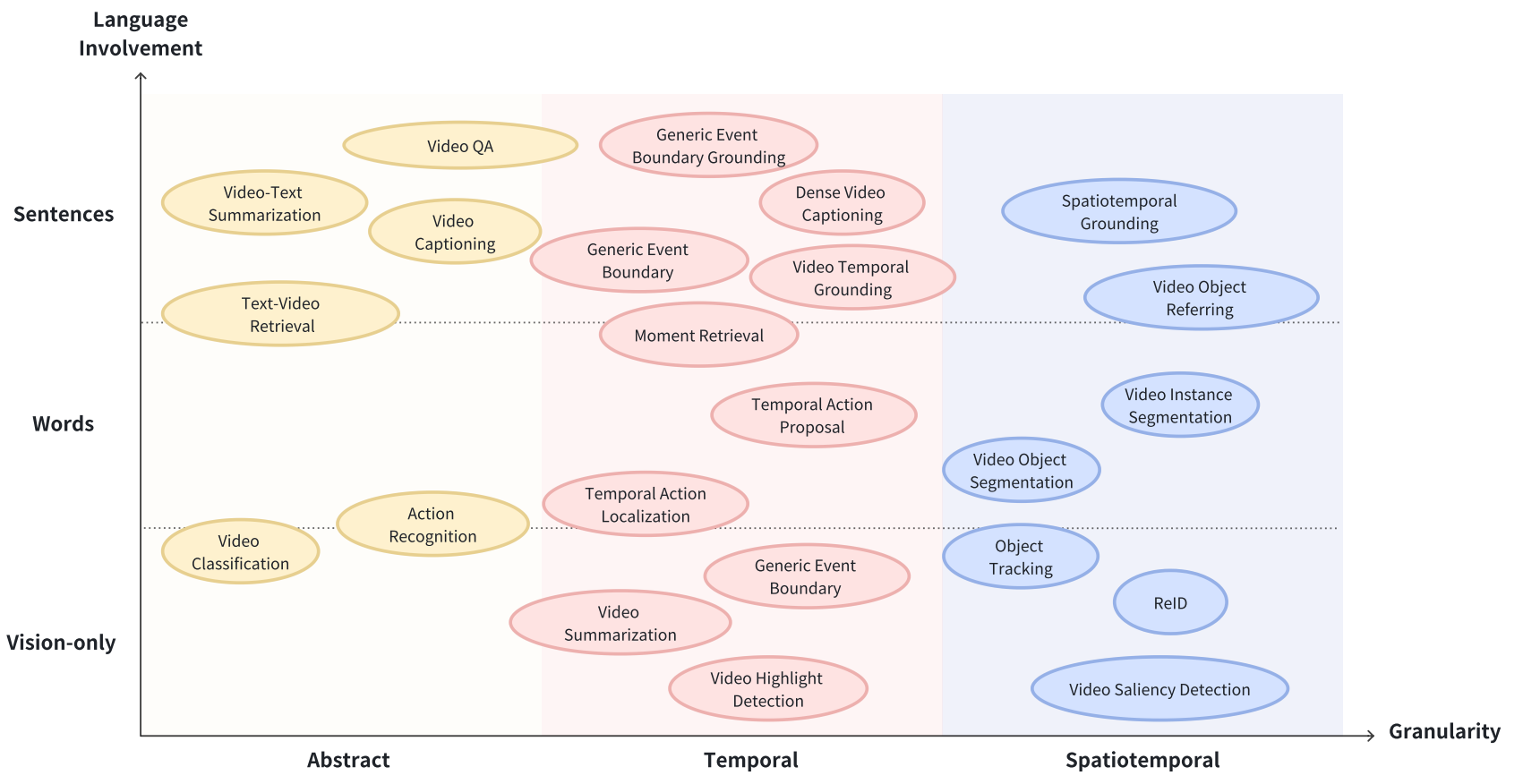
Abstract(抽象) Understanding Tasks: Video Classification, Action Recognition, Text-Video Retrieval, Video-to-Text Summarization, Video Captioning(字幕).
-
Temporal(时间)Understanding Tasks: Video Summarization, Video Highlight Detection, Temporal Action/Event Localization, Temporal Action Proposal Generation(时间动作提案生成), Video Temporal Grounding(视频时序定位), Moment Retrieval, Generic Event Boundary Detection(通用事件边界检测), Generic Event Boundary Captioning & Grounding, Dense Video Captioning.
-
Spatiotemporal(时空) Understanding Tasks: Object Tracking(追踪), Re-Identification(ReID), Video Saliency Detection(视频显著性检测), Video Object Segmentation, Video Instance Segmentation, Video Object Referring Segmentation, Spatiotemporal Grounding.
1.2 部分任务介绍
- Temporal Action/Event Localization: 识别视频中的动作或事件的精确时间片段。
- Temporal Action Proposal Generation: 生成可能包含动作或时间的候选片段。
- Video Temporal Grounding: 文本查询特定时刻的任务。
- Generic Event Boundary Detection(通用事件边界检测): 识别不同事件或活动的过渡点。
- Re-Identification(ReID): 不同视频帧或摄像机视图中识别和匹配个人。
- Video Saliency Detection(视频显著性检测): 识别视频中视觉上最重要或最引人注目的区域。
- Video Object Referring Segmentation: 旨在根据自然语言表达来标记视频中对象实例。
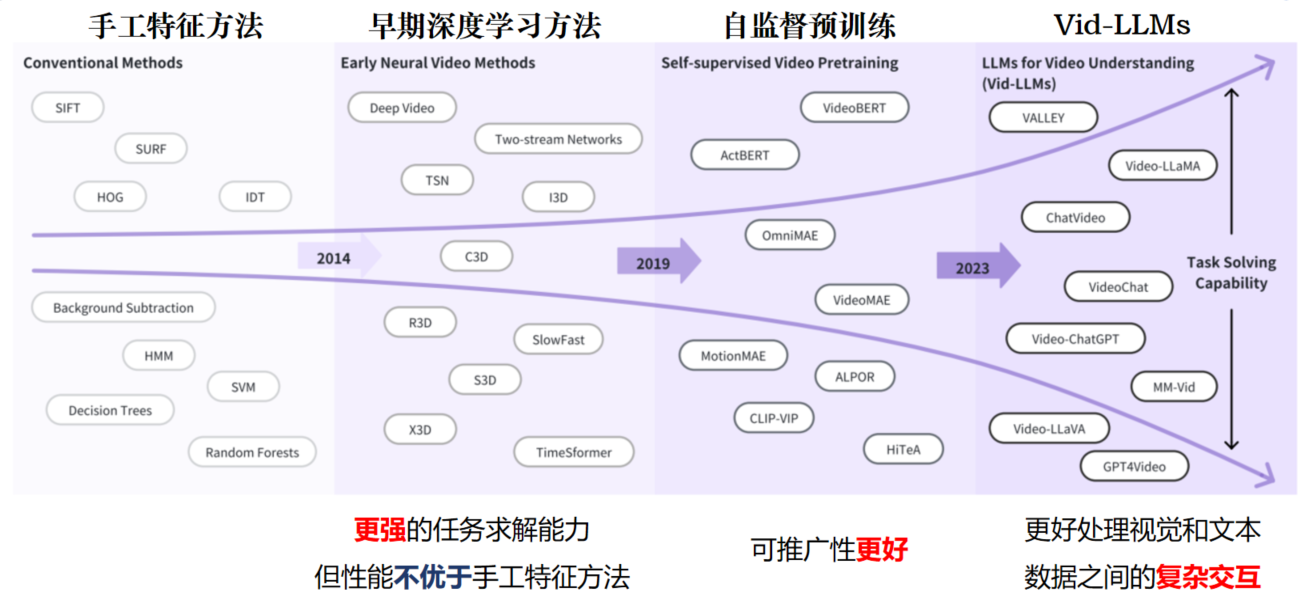
二、Vid-LLM分类
Vid-LLMs的三个主要框架: 1) Video Analyzer×LLM:Video Analyzer将视频输入转换为LLM的文本分析。
2) Video Embedder × LLM:Video Embedder生成向量表示嵌入供LLM处理。
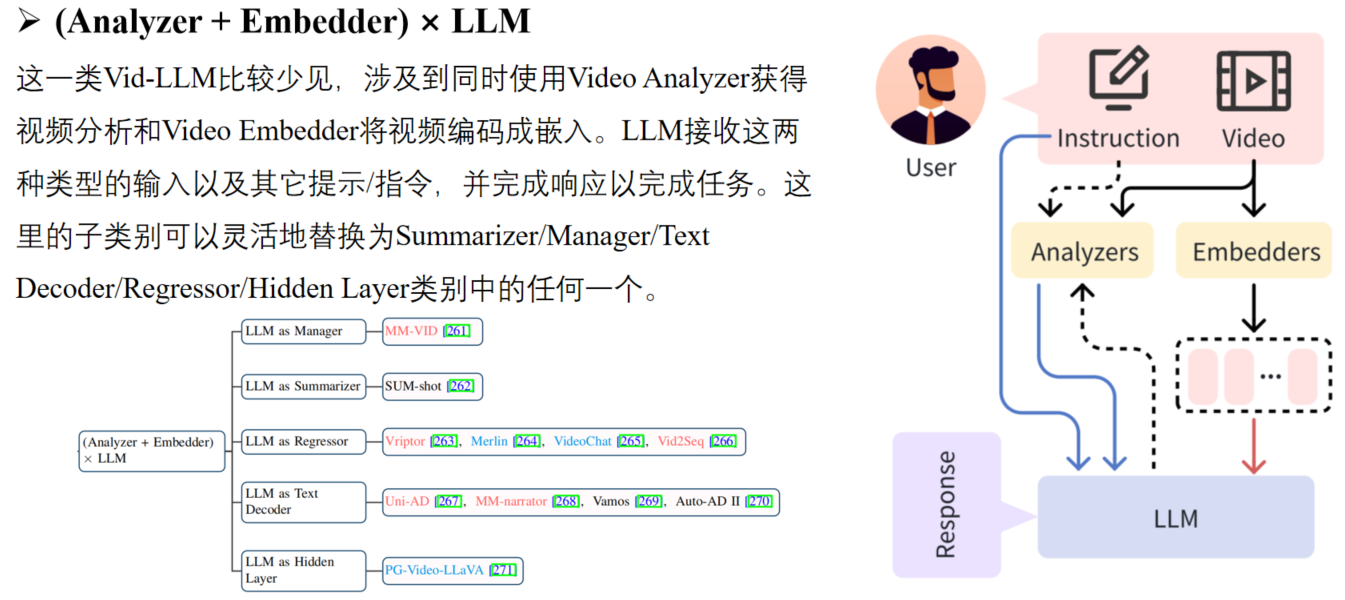
2) (Analyzer + Embedder) × LLM:结合分析器和嵌入器的混合方法,为LLM提供文本分析和嵌入。
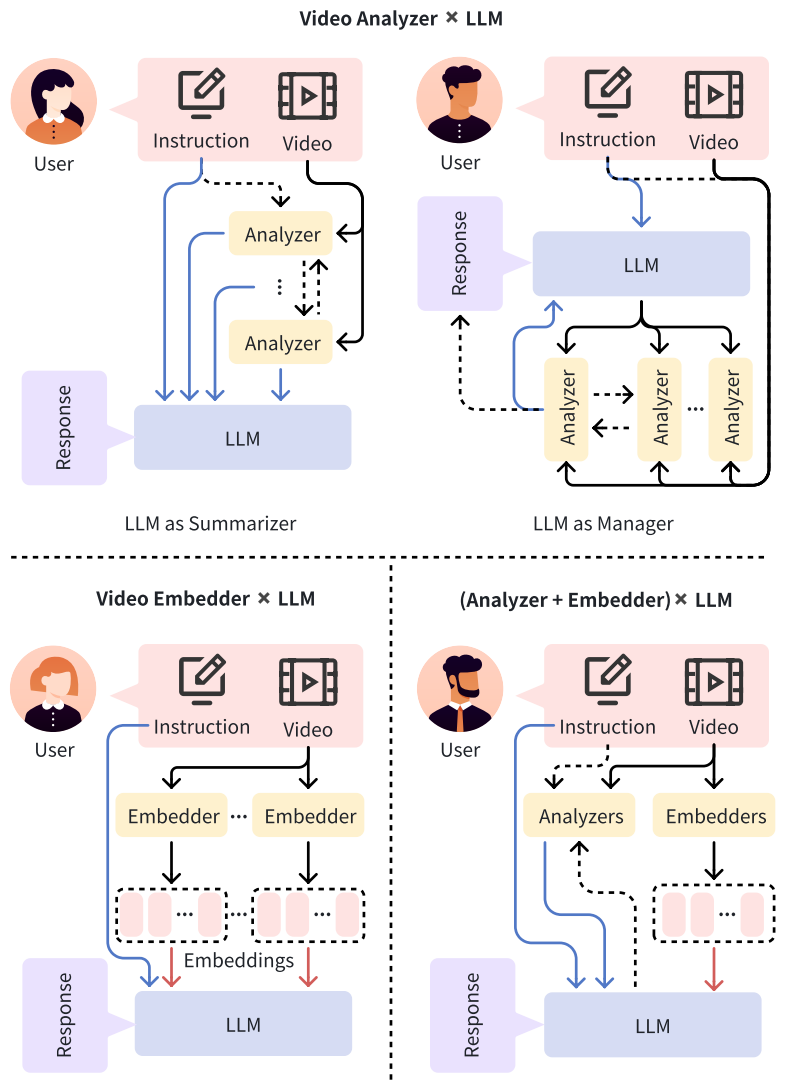
其中 箭头表示信息流的方向,虚线箭头表示可选路径,蓝色箭头表示文本信息流,红色箭头表示嵌入。
2.1 Video Analyzer × LLM
Video Analyzer的定义是一个模块,它将视频输入并输出视频分析(通常是文本形式),便于LLM处理。 该文本可能包括视频字幕、密集视频字幕(视频中所有事件的详细描述和时间戳)、对象跟踪结果(标签、IDs和对象的边界框),以及视频中存在的其他模态的transcripts(转录本),例如:来自ASR的语音识别结果或来自OCR的字幕识别结果。 Video Analyzer生成的文本可以直接送到后续的LLM中,也可以在馈送到LLM之前插入到预先准备好的模板中,或者转换为临时数据库格式供LLM稍后检索。
Video Analyzer × LLM可以分为两个子类:LLM as Summarizer和LLM as Manager。


2.2 Video Embedder × LLM
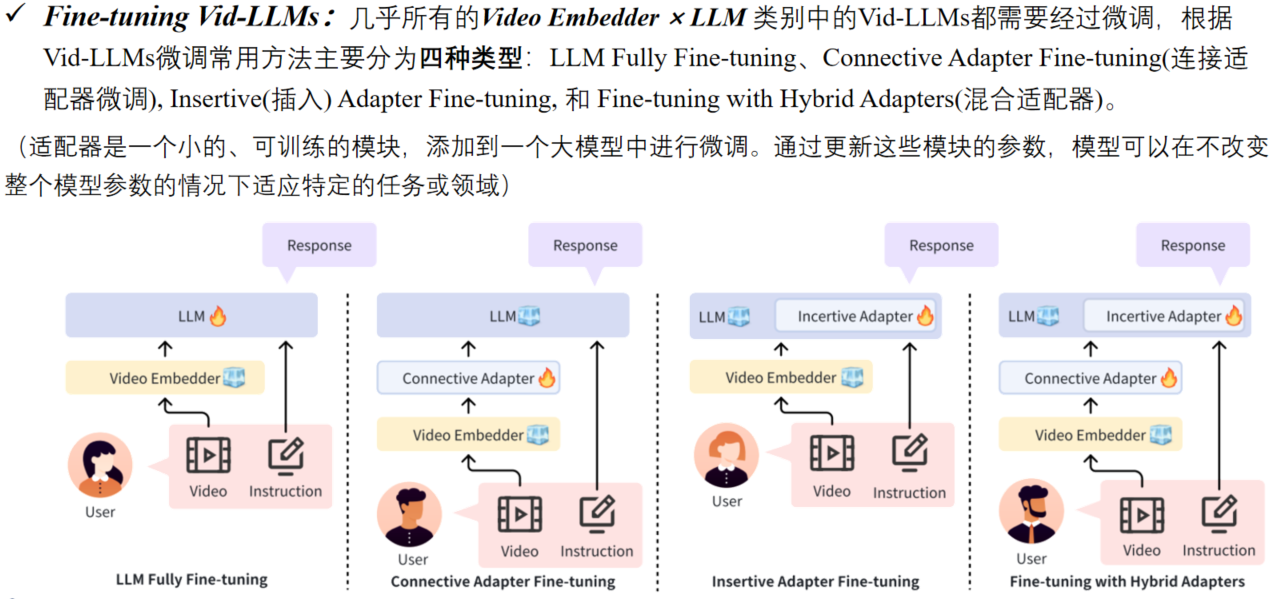
Video Embedder通常是指visual backbone/video encoder,如ViT或CLIP,用于将输入视频转换为vector representations,称为video embeddings或video tokens。 注意:一些Embedder encoder在视频中编码其他模态,例如音频(例如,CLAP),它们也在这里归类为Video Embedder,不将LLM’s tokenizer视为Embedder。 与视频分析器生成的文本不同,视频嵌入器生成的向量不能被LLM直接利用,通常需要一个adapter(适配器)将这些embeddings从视觉语义空间映射到LLM input tokens的text semantic space(文本语义空间)。 根据LLM在Vid-LLM的功能,可以分为三个子类:LLM as Text Decoder、LLM as Regressor和LLM as Hidden Layer。


三、Vid-LLM训练策略
Training-free Vid LLMs: 许多Vid-LLMs建立在强大的LLMs基础上,具有强大的zero-shot、in-context和Chain-of-Thought能力,Video Analyzer × LLM类别中的大多数都是Training-free的,因为来自视频或者其他模态的信息都已经被解析成文本,视频理解任务转换为了文本理解任务。


四、Benchmarks & Evaluation
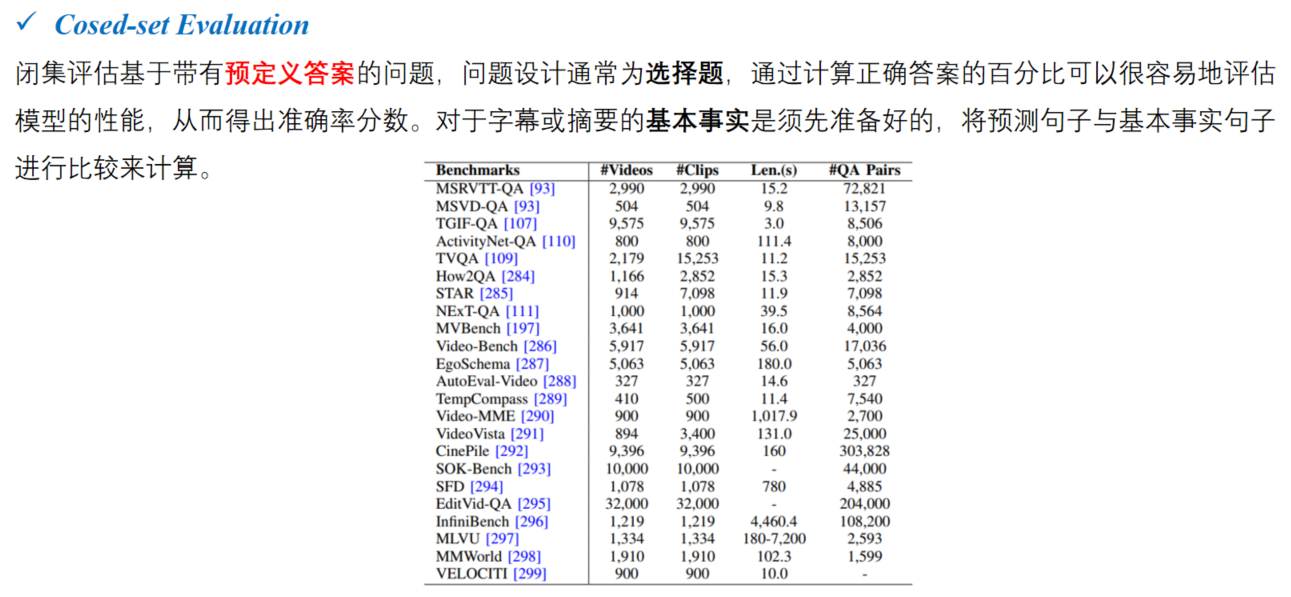
现有的视频问答模型和相关任务的评价方法,分为三种:close-set evaluation 闭集评估、open-set evaluation1 开集评估和 other evaluation methods 其它评估方法。
闭集评估: 依赖于带有预定义答案的问答,通过计算正确答案的百分比来衡量模型的性能。通常使用CIDEr、METEOR、ROUGE和SPICE等指标将预测结果与实际情况进行比较。
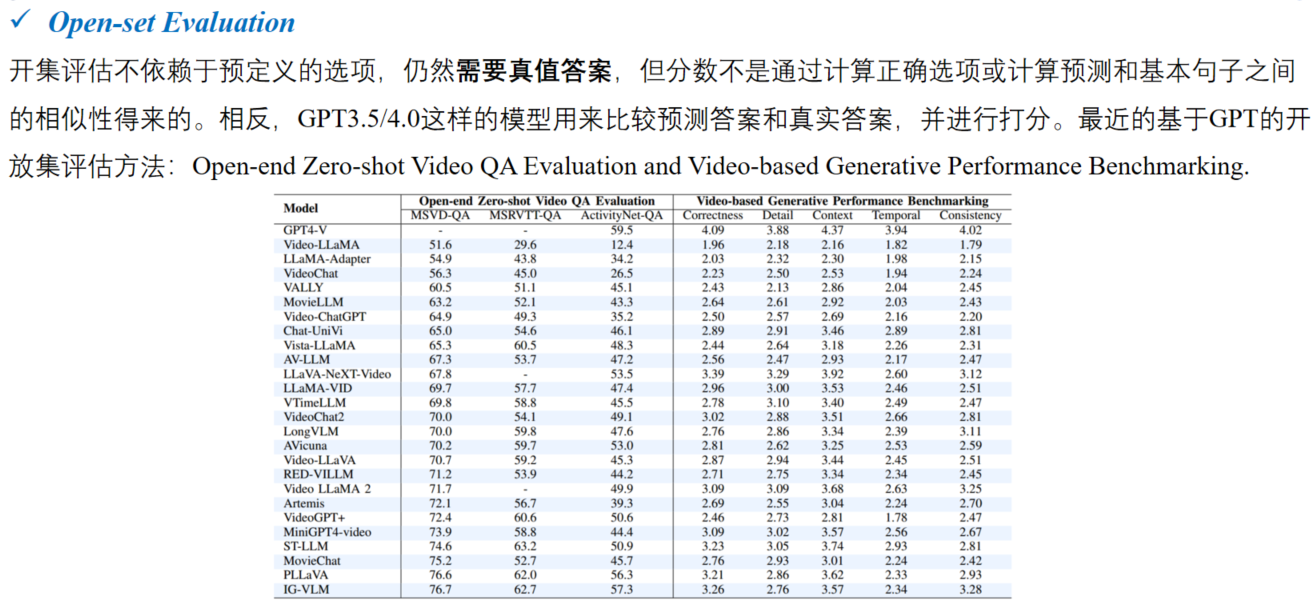
开集评估: 不依赖于预定义的选项,但仍然需要基本的真实答案来评分,通常使用像GPT-3.5/4.0这样的模型来比较预测和评估分数。
其它评估方法: 包括需要细粒度时间和时空理解的任务,如:密集字幕、视频时间基础、时空基础和对象跟踪,使用IoU、Recall**@K和mAP。
人工评估方法: 耗时耗力…