说明:Google提出的一个视频编码器可以cover各种视频理解任务?
目录
一、VideoPrism的介绍
VideoPrism是一款通用的视频编码器,通过从单个冻结模型生成视频表示,能够在广泛的视频理解任务中实现最先进的结果(包括分类、定位、检索和问答等)。

二、VideoPrism的贡献
- 提倡一种可扩展的策略来收集预训练数据,将人工字幕和包含噪声文本描述的视频相结合。
理解: 预训练数据是基础模型的基础,理想情况下,这些数据应该涵盖世界上所有视频的代表性样本(即:预训练数据(视频)很重要)。虽然大多数视频没有对应的文本描述,但是如果这类文本描述存在时,可以为视频内容提供语义层面的信息。(即:视频最好配文本)此外,由于video-text对相对稀缺,所以应当充分利用可获得的video-text对。最后,组合36M高质量和582M带有噪声的video-text对(例如:ASR转录文本、生成的字幕等)构成预训练数据。
- 针对这种混合数据,设计了一种独特的两阶段训练方法。
阶段一: 利用 video-language对比学习 来获取语义 (其实有点好奇为啥论文中写的是video-language,而不是video-text) 。
阶段二: 通过 global-local distillation(全局-局部蒸馏)和 token shuffling(token洗牌)来改进masked video modeling。
- 在33个不同benchmarks上对四大类理解任务进行了全面的评估,VideoPrism的表现在31个benchmarks中明显优于现有的ViFMs(Video foundation models,视频基础模型),展现了VideoPrism的强大泛化能力。
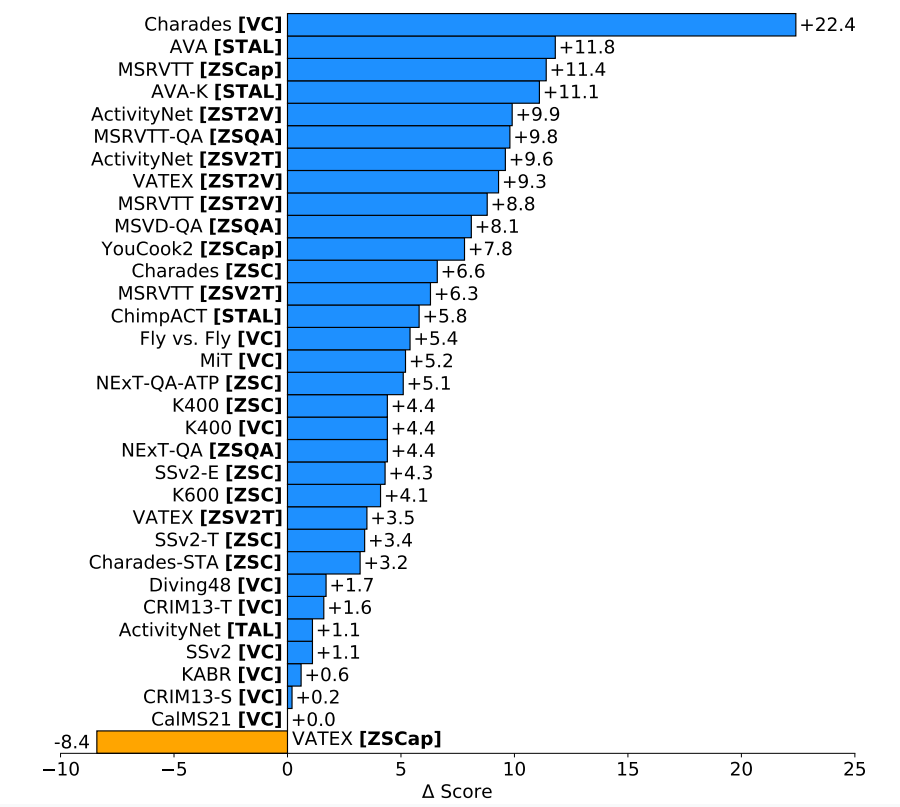
三、预训练数据集
预训练数据由36M个具有高质量的手动标注字幕视频片段和582M个具有噪音的字幕片段组成。
其中,Anonymous-Corpus是最大的高质量视频集,但是仍然比可用的image-language数据集少一个数量级。
四、模型架构说明
VideoPrism模型源于standard Vision Transformer(ViT),并在ViViT之后进行了空间和时间的解耦设计。但是VideoPrism在空间编码器之后删除了ViViT的全局平均池化层,从而使得时空维度保持了output token sequence,从而促进了需要细粒度特征的下游任务。
模型有着两种配置:VideoPrism-g和VideoPrism-B。VideoPrism-g是基于ViT-gaint网络(有1B参数量的空间编码器),VideoPrism-B是ViT-Base网络的一个较小的变体。
五、模型训练算法
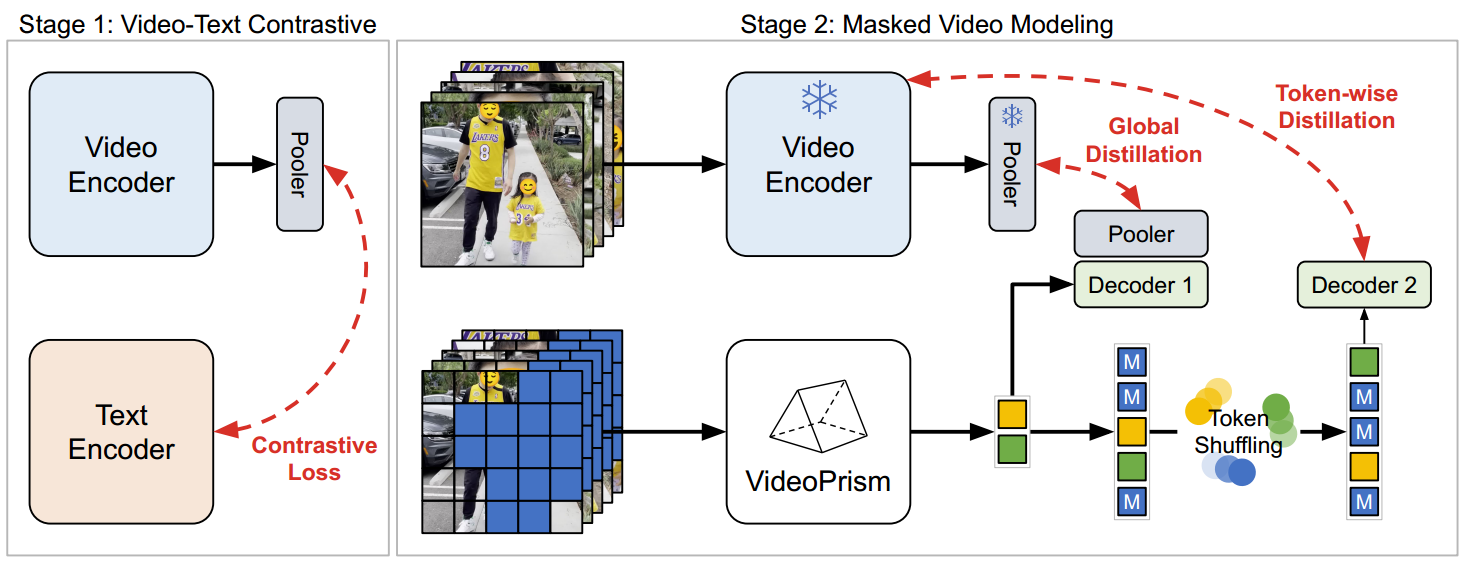
阶段一:Video-Text对比学习
使用CoCa的图像模型来初始化空间编码器,并将WebLI纳入预训练。(大约有1B张带有alt-text的图像,alt-text也叫替代文本,是对图片的文本描述)
在计算对比损失之前,Video Encoder的特征会通过 muti-head attention pooler(MAP) 进行聚合。
借助对比学习,使用所有的视频文本对,将视频编码器和文本编码器对齐:在一个mini-batch中最小化所有video-text pairs的交叉熵损失。
阶段二:Masked Video Modeling
因为阶段一中仅使用vision-text data训练是存在挑战的:文本描述可能是有噪声的,并且它们通常捕获的是外观而不是运动。为了解决这个问题,第二阶段训练侧重于从视频数据中同时学习外观和运动信息。
参考了成功的案例:masked autoencoding for motion understanding(基于运动理解的掩码自动编码器,有点类似BERT技术),于是把这个方法应用到第二阶段,同时确保第一阶段获得的语义知识。
对此,作者对masked autoencoding进行了两个改进:
- 一种新的Token Shuffling方法,进而防止token走捷径。
- global和token-wise 蒸馏损失,以有效地利用第一阶段获得的知识。
使用冻结的Stage-1 Encoder处理unmasked的3D video patches来产生整个视频的全局语义嵌入和token-wise embeddings(我理解的是每个时间点的局部嵌入)。
- Token shuffling(Token洗牌): 当使用第一阶段初始化第二阶段模型时,一个问题是:解码器可能会复制粘贴,还有个问题是:解码器只预测被masked的token。因此,进行token shuffling,并向该序列添加位置嵌入。一方面可以避免解码器直接复制粘贴。另一方面可以类似于Jigsaw puzzles(拼图游戏),解码器试图解决unmasked tokens,同时预测masked token。

- Global-local distillation(全局-局部蒸馏): 与图像的掩码蒸馏不同,发现只使用masked modeling loss时,Stage-2的模型在外观繁重任务上表现不如Stage-2的模型,可能是因为Stage-2预训练中的灾难性遗忘,为了缓解这个问题,增加了额外的损失,让Stage-2模型使用从Stage-1那里提取完整视频的全局嵌入。
六、实验
评估 FMs 在VideoGLUE benchmark with frozen backbones:
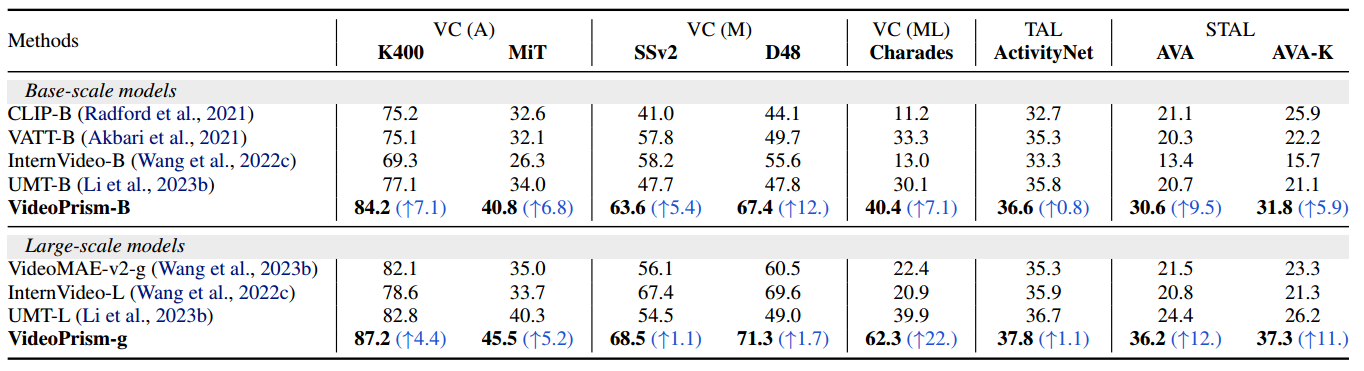
zero-shot video-text retrieval的评估结果:
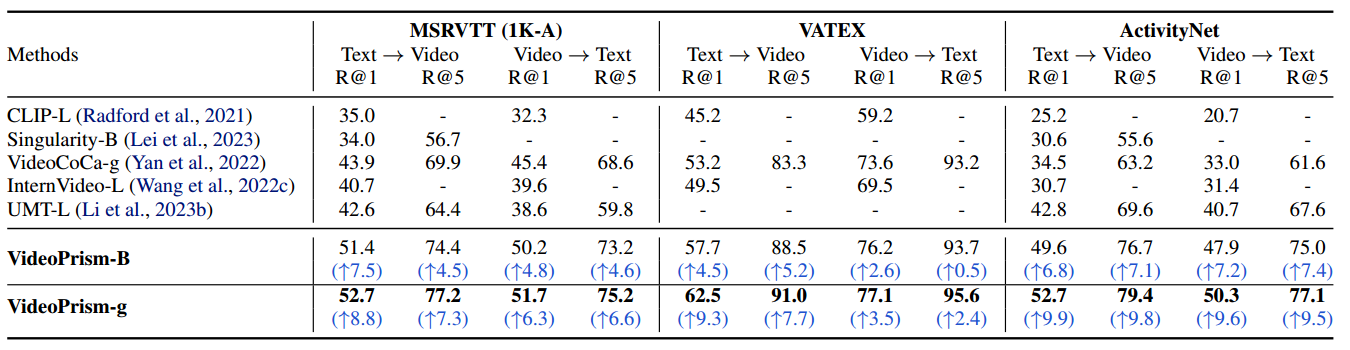
zero-shot video classification任务中和SOTA结果比较:
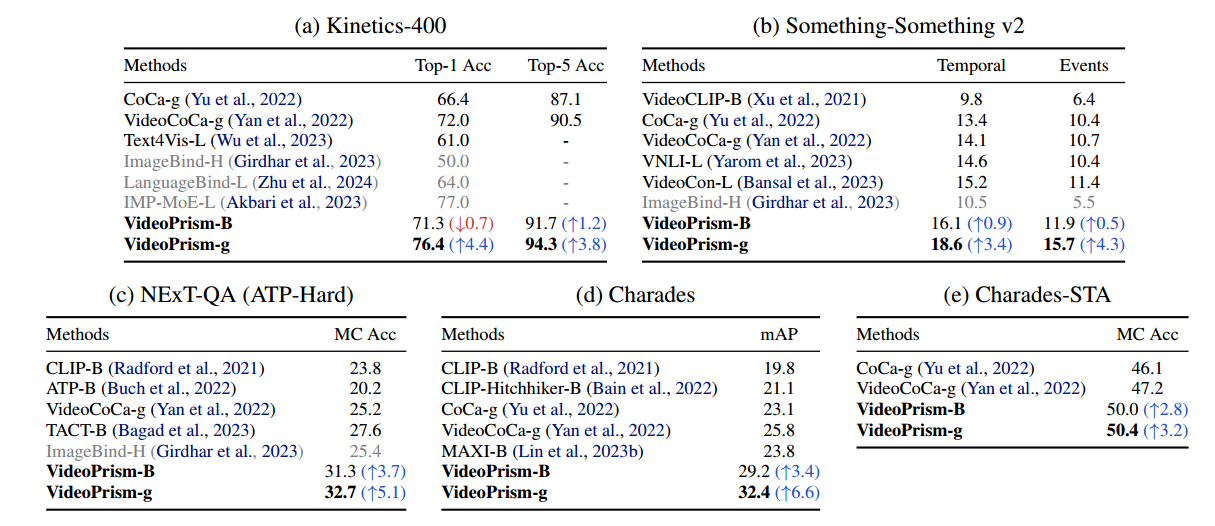
zero-shot video captioning任务中和SOTA结果比较:
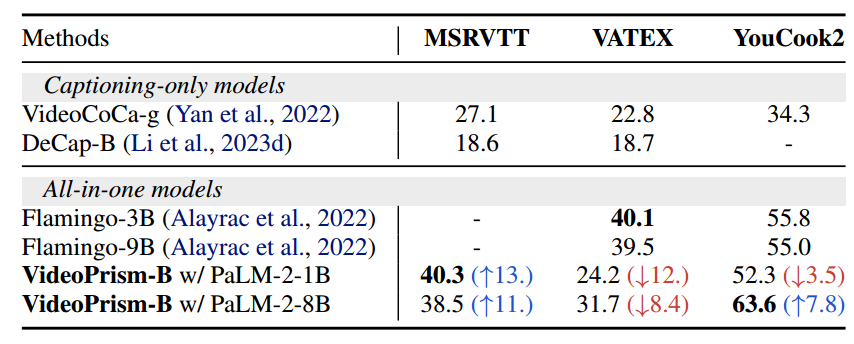
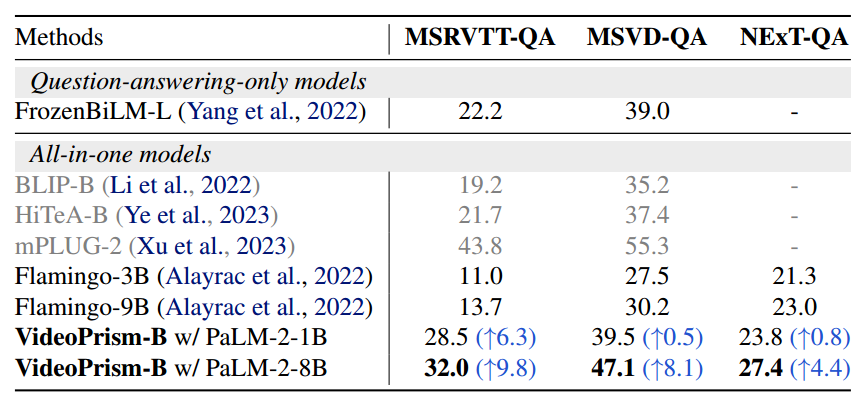
zero-shot video QA任务中和SOTA结果比较:
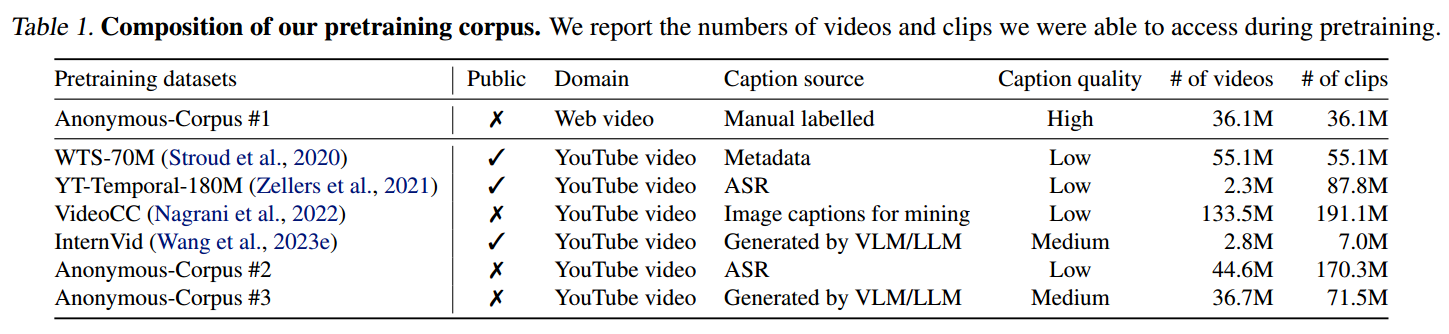
CV for Science benchmarks和SOTA结果比较: