说明:嗯?Wolf狼?让我瞧瞧这是个啥!
目录
一、为什么提出Wolf
-
代码链接: https://github.com/Boyiliee/(好像没开源,神奇链接到作者的GitHub主页…)
1.1 视频字幕的重要性
-
视频字幕能够提供准确、可搜索的描述,促进 内容的理解和检索。
-
视频字幕能够为Sora、Runaway等 视频生成 任务的基础模型提供了成对数据。
1.2 视频字幕目前存在的问题
-
高质量的标记数据稀缺。 来自互联网的视频字幕可能有错误和不一致,而人工注释对于大型数据集是非常昂贵的。
-
时间相关性和摄像机运动的额外复杂性。 现有字幕模型在时间推理方面存在问题,无法实现准确的场景推理。
-
缺乏benchmark来衡量视频字幕生成质量。 现有的视频QA benchmarks通过仅限于简短的答案呢,这使得很难在长标题中测量出幻觉。
-
字幕正确性和完整性 对于safety-critical任务是至关重要的,对场景的错误或不完整描述可能导致严重后果。
二、Wolf贡献
-
设计了第一个用于WOrLd Summarization Framework(世界概括框架),并引入了LLM-based度量CapScore来评估字幕的质量。结果表明,Wolf的方法大大提高了CapScore。
-
介绍了Wolf benchmark和四个人工标注的数据集(涵盖了:自动驾驶,Pexels的场景,机器人视频,人类注释的字幕),称之为Wolf数据集。
三、Wolf模型
Wolf是一个自动字幕摘要框架,采用混合专家的方法为视频生成长、准确和详细的字幕。主要使用了CogAgent和GPT-4V生成图像级字幕,使用VILA-1.5和Gemini-Pro-1.5生成视频级字幕。
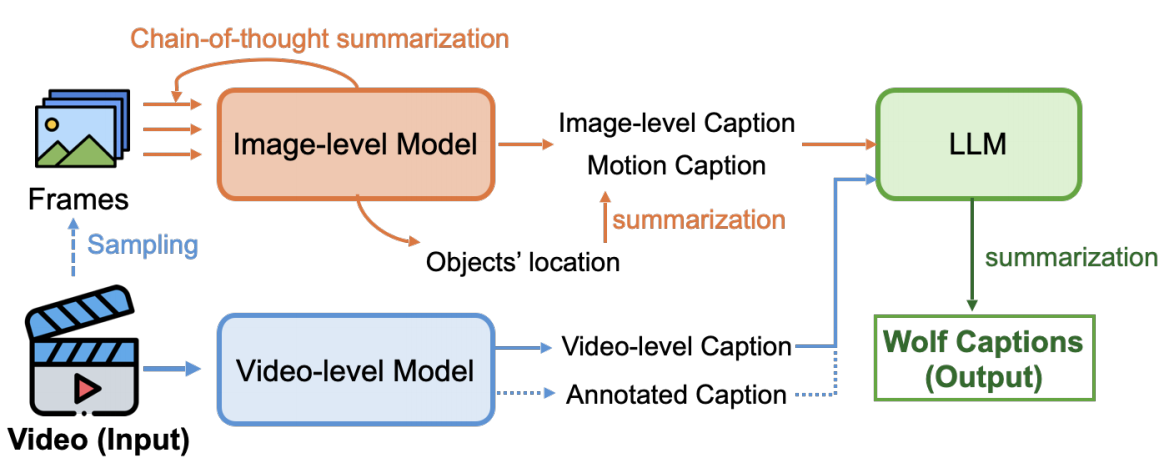
3.1 图像级模型中的思维链
由于图像级模型(image-based VLMs)比视频级模型(video-based VLMs)使用了更多的数据进行预训练。因此,使用了基于图像的VLMs来生成字幕,并设计了一个思维链从图像级模型中获取视频字幕。
首先,将视频分割 为连续的图像:每秒采样两个关键帧。将图像1输入到图像级模型 以获得字幕1(需要生成详细的场景级信息和物体位置)。
然后,考虑到视频关键帧之间的时间相关性 ,然后将字幕1和图像2都输入到模型中生成字幕2。
接着,不断重复上面步骤。进而为所有的采样帧生成字幕。
最后,使用GPT-4对所有的字幕信息进行汇总,并提示: Summarize all the captions to describe the video with accurate temporal information。
3.2 LLM-based 的视频总结
使用prompt: Please summarize on the visual and narrative elements of the video in detail from descriptions from Image Models (Image-level Caption and Motion Caption) and descriptions from Video Models (Video-level Caption) 详细总结了视频的视觉和叙事元素。
还可以向摘要里面添加带注释的字幕,基于这个简单的方案,Wolf可以捕捉到丰富多样的视频细节,进而减少冗余和幻觉。Wolf认为这是因为LLM可以识别并消除不一致或错误的字幕。
获得了图像级和视频级模型的描述后,接下来应用提示:Please describe the visual and narrative elements of the video in detail, particularly the motion behavior进而细化视频描述 (鼓励详细说明视频中的动态变化和情节发展)

上面的图展示了自动驾驶(左),Pexels(右上)和机器人学习视频数据集(右下)的视频和相应的人工注释字幕,目前共计25.7小时。
四、Wolf Benchmark:视频字幕的基准
构建了四个数据集: 两个基于开源的NuScenes数据集的自动驾驶视频字幕数据集,一个来自Pexels的通用日常视频字幕数据集,一个来自开源机器人学习数据集的机器人操作视频字幕数据集。
这些benchmark数据集用于评估字幕模型的场景理解能力和行为理解能力,所有的字幕都是使用基础真相信息、基于规则的启发式、人工标记和基于GPT重写的组合生成的。
4.1 数据集介绍
4.1.1 NuScenes数据集
NuScenes数据集是一个大规模旨在加速自动驾驶 研究的数据集。展示了1000个注释场景,每一个场景由一个20秒的驾驶视频剪辑而成。包含500对强烈互动的视频字幕对(≈0.7小时),以及4785对正常驾驶场景视频字幕对(≈6小时)字幕生成过程包括:Agent-level motion annotation、Ego-centric interaction annotation、GPT-rewriting
-
Agent-level motion annotation(代理级运动注释): NuScenes提供了每个场景中交通元素的完整注释,包括:交通元素的三维边界框和类别、语义地图信息。提供了智能体的11种动作类别,如:停止、加速、减速、变道和转弯等。
-
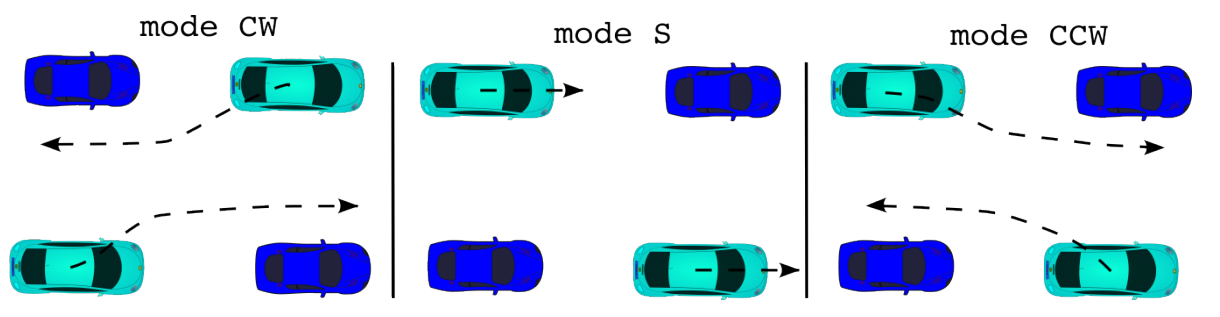
Ego-centric interaction annotation(以自我为中心的交互注释): 描述了视频片段中自我车辆与其它交通参与者的互动(例如:穿过行人,阻塞交通锥等),编码了自我车道与其它交通参与者车道之间的拓扑关系,包括:left、right、ahead、behind、noton(noton描述了不在交通场景的车,如停在停车场的车);描述了一对智能体之间的相对运动 ,包括:静态、顺时针、逆时针。
- GPT-rewriting(GPT重写): 将上述所有信息结合在一起,利用启发式来注释视频片段中显示的交互。从NuScenes数据集中确定了6个交互类别:①绕过阻塞的交通锥以绕过施工区域;②对过路行人退让;③对来袭车辆退让;④跨过车道分隔线超车;⑤通过变道超车;⑥其他非密集互动。
4.1.2 Robot Manipulation Dataset数据集
收集了100个机器人操作 视频(每个视频5秒到1分钟不等),这些视频展示了机器人在各种环境下的复杂操作(例如:取放、推等),包括厨房、办公室、实验室和开放世界,手动为每个视频添加了字幕。
4.1.3 Pexels Dataset数据集
收集了360p到1080p的高质量日常环境 视频,每个视频长度从10秒到2分钟不等,内容包含15个类别。
4.2 评估指标和排行榜
4.2.1 CapScore:用LLM评估字幕
这是一个使用了LLM(GPT-4)来评估预测和人工注释字幕之间的相似性的定量指标。要求GPT-4输出两个分数:字幕相似度(每个字幕与基本事实字幕的相似程度,是否抓住了基本事实的主题和细节)和字幕质量(说明字幕和真实字幕相比是否减少了幻觉和错误)。
假设有6个字幕,将所有的字幕输入到GPT-4并添加提示:
“Can you give a score (two decimal places) from 0 to 1 for captions 1, 2, 3, 4 and 5, indicating which one is closer to the ground truth caption (metric 1) and which contains fewer hallucinations and less misalignment (metric 2)? Please output only the scores of each metric separated only by a semicolon. For each metric, please output only the scores of captions 1, 2, 3, 4 and 5 separated by commas, in order—no text in the output. ”
4.2.2 Benchmarking Video Captioning 视频字幕基准
因为缺乏一个标准的平台来评估VLM在视频理解方面的表现,因此开发了首个视频字幕排行榜。
排行榜链接:https://wolfv0.github.io/leaderboard.html
五、实验结果
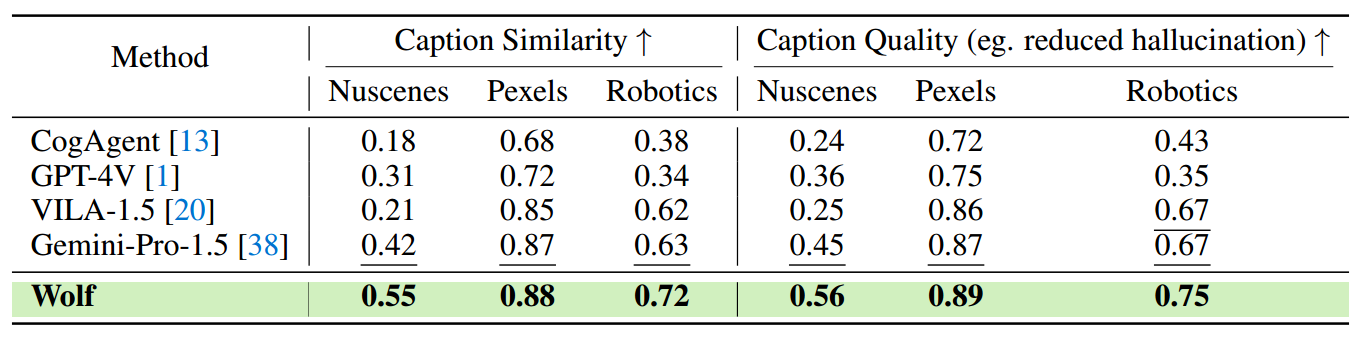
比较500个高难度互动(难度和挑战性)的Nuscenes视频,473个Pexels视频和100个机器人视频:
比较4,785个正常Nuscenes视频:

六、讨论和未来工作
Wolf认为应当有效地使用GPU资源: 所有模型量化为4位,以进一步提高效率。现在的GPU是8位计算,因此可以容纳两个4位进行计算。并且下一代GPU将原生支持4位数据类型,因此期望量化为4位。
Wolf认为应当多关注安全: 例如,在驾驶场景中,对道路周围树叶的详细描述,即使是正确的,也是不相关的,可能会成为决策者的分心。因此,需要一种方法来衡量字幕与任务的匹配程度,并开发一个高级版本的CapScore。最后,我们需要一种方法来量化对字幕的confidence,通过利用学习理论中的技术,如共形预测。